The following example illustrates how we can optimize a simple matrix multiply algorithm by using performance data from TAU and PAPI. TAU is installed using
% configure -papi=<papidir> -MULTIPLECOUNTERS -PAPIWALLCLOCK

In the above figure, we see the original code (Figure A, top left) of the matrix multiply algorithm. We hand-instrument the main matrix multiply loop that computes the dot product of two matrices using TAU timers. We set the following environment variables before executing the program:
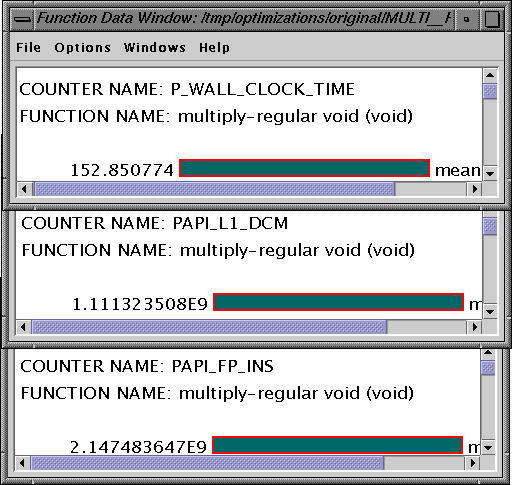
% setenv COUNTER1 PAPI_FP_INS % setenv COUNTER2 PAPI_L1_DCM % setenv COUNTER3 P_WALL_CLOCK_TIMEThis allows us to measure floating point instructions, level 1 cache misses and the wallclock time respectively. When the program is executed on a Pentium III/500 MHz Xeon proccessor, it takes 152.85 secs of wallclock time, executes 2.14 E9 floating point operations and has 1.11E9 data cache misses in the main instrumented loop as reported by TAU using PAPI (shown below). We can verify that the number of floating point instructions executed matches what we'd expect the matrix multiply loop to execute (for problem size n=1024, 2*n^3 = 2.14E9). The source code of the original program is available here.
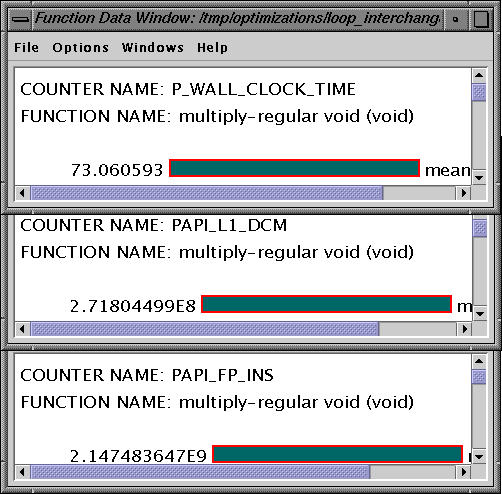
With this change, the wallclock time reduces to 73.06 secs, and we see an order of magnitude decrease in the number of data cache misses while retaining the number of floating point instructions. The source code of the modified program is available here.
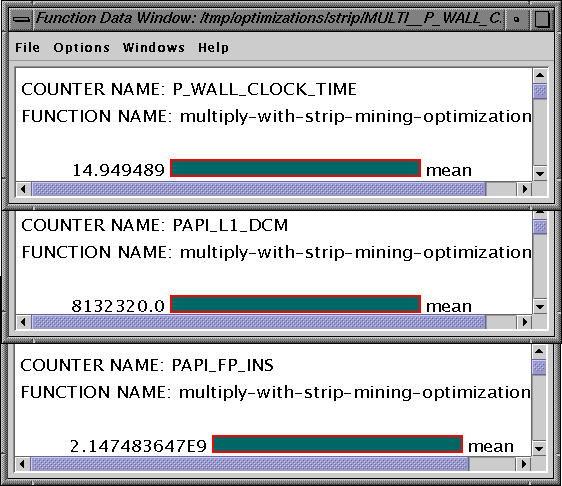
We observe that this has a dramatic effect and reduces the numberr of data cache misses from 1E9 to 8.1E6. This reduces the wallclock time from 152 secs to 14.94 secs while keeping the same floating point instructions constant. The source code of the modified program is available here.
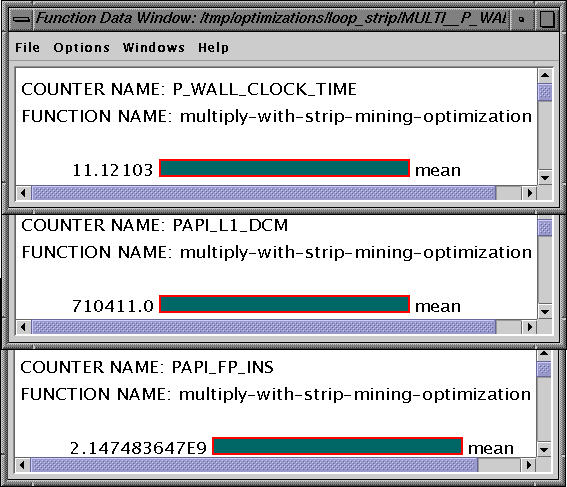
We notice that the time taken reduces from 152 secs to 11.12 secs and the number of data cache misses reduces from 1E9 to 7.1E5. The source code for this modification is available here.
These examples are available here: papitau.tar.gz.
This example illustrates how we can observe the effect of changes in the source code on the overall performance of the application using PAPI and TAU.
Optimization: Strip mining with loop interchange
Finally, we combine the loop interchange and strip mining optimizations to produce code in Figure (D). The performance data for the main loop is shown below: