
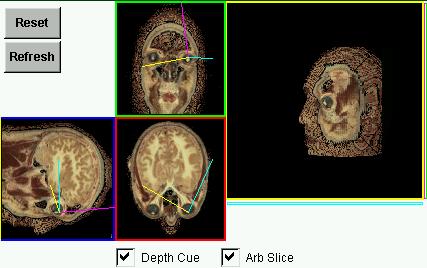
This first project caused me to wonder just what
could a Java Applet be expected to be able to do in terms of interactive
solid rendering. I had some zebra fish embryo data, but one of the qualities
which make zebra fish attractive to researchers is that as embryos the
are virtually transparent, unfortunately this also makes them quite boring
to look at. So I resorted to data from the Visible Human Project thanks
to the The National Library of
Medicine. My first attempt involved pre generating all the front,
top and side images as .gifs and sending them when they were asked for.
It soon became clear sending individual images over a phone line
was never going to match my idea of interactive. So I put all the original
images together at once and chose a 256 color palette, and generated an
array of bytes which were pointers from the color of a pixel in the serial
image to the color palette. Now you are not sending any duplicate data
as you must with individual images nor are you sending headers or opening
closing sockets etc. Now when you reconstitute the data back into images
why stop at front, top and side when you can generate any plane, and why
stop with those pixels which happen to fall exactly on the plane when there
is data at hand which could give your image more context. To this end I
sorted the palette by "brightness" and when putting a color in the
finished image which was not actually on the image plane I would replace
that color with one from further towards the darker end of the palette
which gives a passable representation of depth.
To prepare (reduce) the data I used Unix shell scripts, the NetPbm
library and a couple of small C programs.
(note: I am interested in hearing about appropriate
existing file formats for this sort of data if anyone knows of any.)
A good future project would be to write a java app to generate the
models from a directory of serial images so people could more readily build
their own. A questions I am curious about from this stage has to do with
color quantisization, presently I put all of the images in one long strip
and drop it from 24 bits to 8 bits but when choosing these 256 colors,
their neighbors should be taken into account and not just the neighbors
within the 2D slice. Also when the images are lined up in a strip, artificial
neighbors are created between slices which will incorrectly influence the
overall choice of color, what should happen is the colors be quantified
in 3D.
One of the primary questions I had wanted to answer when beginning Sushi
is:
Given that some image data is acquired at a slow or spastic rate due
to transmission or how it is generated.
And that the interesting data is typically found near the center of
an image with some border around it,
How would it work if an image were built from the center out?
This way the most interesting part would be presented in full detail
before any irrelevant boarder material is encountered. Which allows for
an early abort if the image is not what you were looking for and a visually
un-distracting finish if it is.
As it turns out, for this application, this process also forms an efficient
strategy for searching for "additional" image data by first searching at
the edges of the primary image, where it is most likely to be found.
There is currently some interest in Sushi being used as an internet
teaching tool for biology,
Hence the chick embryo -- but with that Professor out of the country
its been pretty quiet.
(left over ranting ... )
However with an applet you lose the ability to define a heap size &
stack size so effort had to be made to minimize memory usage since the
higher the frame rate the faster garbage is generated. Also though you
may request garbage removal at any time, by my observations, browsers will
monitor until they reach a predefined level then initiate garbage collection,
the problem this applet has is it generates garbage at a rate the browsers
are not expecting so before they can complete their collection they are
out of memory. Life in the big city.
This applet has a fairly large data set. (similar to a hundred 100 by
100 gifs). As a jar archive, it is just over half a meg, however
since I am attempting to reduce incompatibilities with as many browsing
options as I can I am not jarring up the Applet so the data set is
about 1.3 meg. .
Notes on Browsers