With the general strategy above in mind, consider the simulation of the interaction of a shock wave with an interface between two gases. The code employs Structured Adaptive Mesh Refinement [25,26] for solving a set of Partial Differential Equations (PDE) called the Euler equations. Briefly, the method consists of laying a relatively coarse Cartesian mesh over a rectangular domain. Based on some suitable metric, regions requiring further refinement are identified, the grid points flagged and collated into rectangular children patches on which a denser Cartesian mesh is imposed. The refinement factor between parent and child mesh is usually kept constant for a given problem. The process is done recursively, so that one ultimately obtains a hierarchy of patches with different grid densities, with the finest patches overlaying a small part of the domain. The more accurate solution from the finest meshes is periodically interpolated onto the coarser ones. Typically, patches on the coarsest level are processed first, followed recursively by their children patches. Children patches are also processed a set number of times during each recursion.
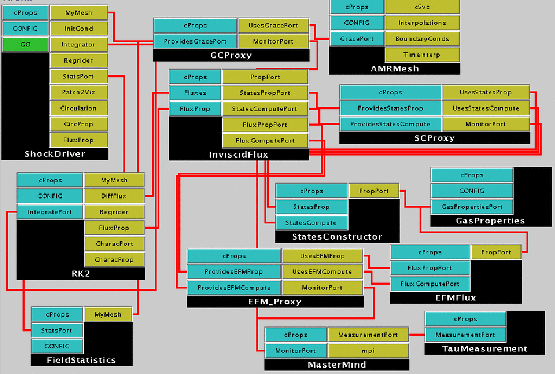
Figure 5 shows the component version of the code developed using the CCAFFEINE [1] CCA framework. On the left is the ShockDriver, a component that orchestrates the simulation. On its right is AMRMesh that manages the patches. The RK2 component below it orchestrates the recursive processing of patches. To its right are States and EFMFlux which are invoked on a patch-by-patch basis. The invocations to States and EFMFlux include a data array (a different one for each patch) and an output array of the same size. Both these components can function in two modes - sequential or strided array access to calculate X- or Y-derivatives respectively - with different performance consequences. Neither of these components involve message passing, most of which is done by AMRMesh.
 |
We used the TAU performance interface and measurement component to model the performance of both States and EFMFlux and analyze the message passing costs of AMRMesh. We also analyzed the performance of another component, GodunovFlux, which can be substituted for EFMFlux. Three proxies were created with performance interfaces and interposed between InviscidFlux and the component in question. A proxy was also written for AMRMesh to capture message-passing costs. An instance of the TAUMeasurement component provided timer support and the Mastermind component was created to record performance measurements for different execution combinations.
The simulation was run on three processors of a cluster of dual 2.8 GHz Pentium Xeons with 512 kB caches. gcc version 3.2 was used for compiling with -O2 optimization. Performance timings revealed about 25% of the time is spent in MPI_Waitsome() which is invoked from two methods in AMRMesh - one that does ``ghost-cell updates'' on patches (gets data from abutting, but off-processor patches onto a patch) and the other that results in load-balancing and domain (re-) decomposition. The other methods, one in States and the other in GodunovFlux are modeled below.
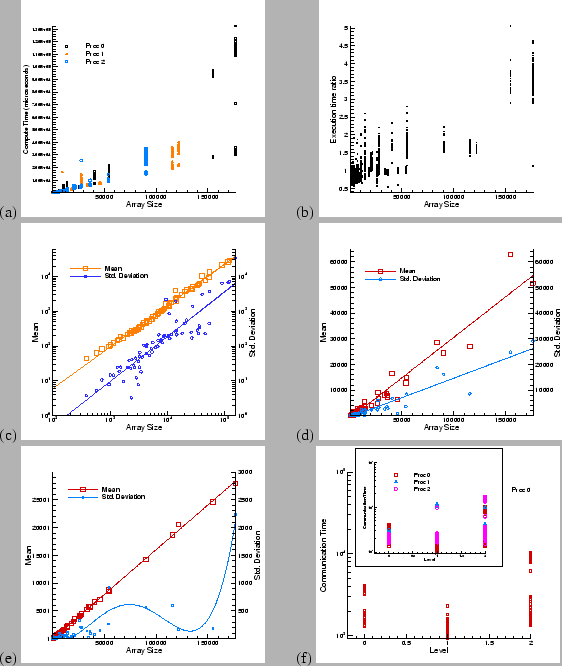
In Figure 6 (a) we plot the execution times for States for both the sequential and strided mode of operation. We see that for small, largely cache-resident arrays, both the modes take roughly the same time. As the arrays overflow the cache, the strided mode becomes more expensive and one sees a localization of timings. In Figure 6 (b), we plot the ratio of strided and sequential access times. The ratio varies ranges from 1 for small arrays to around 4 for large ones. Further, for larger arrays, one observes large scatters. Similar phenomena are also observed for both GodunovFlux and EFMFlux.
During the execution of the application, both the X- and Y-derivatives are calculated and the two modes of operation of these components are invoked in an alternating fashion. Thus, for performance modeling purposes, we consider an average. However, we also include a standard deviation in our analysis to track the variability introduced by the cache. It is expected that both the mean and the standard deviation will be sensitive to the cache size. In Figures 6 (c), 6 (d), and 6 (e), we plot the execution times for the States, GodunovFlux and EFMFlux components. Regression analysis was used to fit simple polynomial and power laws, which are also plotted in the figures. The mean execution time scales linearly with the array size, once the cache effects have been averaged out. The standard deviations exhibit some variability, but they are significant only for GodunovFlux, a component that involves an internal iterative solution for every element of the data array. Note that these timings do not include the cost of the work done in the proxies, since all the extraction and recording of parameters is done outside the timers and counters that actually measure the performance of a component.
If
![]() and
and ![]() are the execution times (in
microseconds) for States, GodunovFlux and EFMFlux
and
are the execution times (in
microseconds) for States, GodunovFlux and EFMFlux
and ![]() the input array size, the best-fit execution time models
for the three components are:
the input array size, the best-fit execution time models
for the three components are:
In Figure 6 (f) we plot the communication time spent at different levels of the grid hierarchy during each communication (``ghost-cell update'') step. We plot data for processor 0 first. During the course of the simulation, the application was load-balanced once, resulting in a different domain decomposition. This is seen in a clustering of message passing times at Level 0 and 2. Ideally, these clusters should have collapsed to a single point; the substantial scatter is caused by fluctuating network loads. Inset, we plot results for all the 3 processors. A similar scatter of data points is seen. Comparing with Figures 6 (c), 6 (d), and 6 (e), we see that message passing times are generally comparable to the purely computational loads of States and GodunovFlux, and it is unlikely that the code, in the current configuration (the given problem and the level of accuracy desired) will scale well. This is also borne out by performance profiles where almost a quarter of the time is shown to be spent in message passing.
The results of this example confirm the advantages of an integrated methodology and infrastructure for performance engineering in component software.