The experiments we conducted were stress tests for the overhead
compensation algorithms. We profiled all routines in the application
source code for flat profiles and we profiled all routine calling
paths for callpath profiles.![]() While the results show the overhead compensation strategies
implemented in TAU are generally effective, we emphasize the need to
have an integrated approach to performance measurement that takes into
account the limits of measurement precision and judicious choice of
events. It should not be expected that performance phenomena
occurring at the same granularity as the measurement overhead can be
observed accurately. Such small events should be eliminated from
instrumentation consideration, improving measurement accuracy overall.
In a similar vein, there is little reason to instrument events of
minor importance to the desired performance analysis.
While the results show the overhead compensation strategies
implemented in TAU are generally effective, we emphasize the need to
have an integrated approach to performance measurement that takes into
account the limits of measurement precision and judicious choice of
events. It should not be expected that performance phenomena
occurring at the same granularity as the measurement overhead can be
observed accurately. Such small events should be eliminated from
instrumentation consideration, improving measurement accuracy overall.
In a similar vein, there is little reason to instrument events of
minor importance to the desired performance analysis.
TAU implements a dynamic profiling approach where events to be profiled are created on-the-fly. This is in contrast with static profiling techniques where all events must be known beforehand [7]. Static approaches can be more efficient in the sense that the event identifiers and profile data structures can be allocated a priori, but these approaches do not work for usage scenarios where events occur dynamically. While TAU's approach is more general, modeling the overhead is more complicated. For instance, we do not currently track event creation overhead, which can occur at any time. Future TAU releases will include this estimate in the overhead calculation. The good news is that we made significant improvements in the efficiency of TAU's profiling system in the course of this research. Our callpath profiling overheads were improved ten times by switching to a more efficient callpath calculation and profile data lookup mechanism.
Callpath profiling is more sensitive to recovery of accurate
performance statistics for two reasons. First, there are more
callpath events than in a flat profile and each callpath event is
proportionally smaller in size. Second, we only estimate the flat
profiling overhead at this time in TAU. The overhead for profiling
measurements of callpaths is greater because the callpath must be
determined on-the-fly with each event entry and the profiling data
structures used must be mapped dynamically at runtime (flat profile
data structures are directly linked). Nevertheless, it is encouraging
how well compensation works with callpath profiling using less exact
(smaller) overhead values. Also, TAU's implementation of callpath
profiling allows the depth of callpath to be controlled at execution
time. A callpath depth of ![]() results in a flat profile. Setting the
callpath depth to
results in a flat profile. Setting the
callpath depth to ![]() results in events for all callpaths of length
results in events for all callpaths of length
![]() being profiled. This callpath depth control can be used to
limit intrusion.
being profiled. This callpath depth control can be used to
limit intrusion.
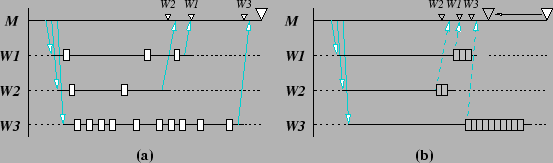
The most important result from the research work is the insight gained on overhead compensation in parallel performance profiling. Our present techniques are necessary for compensating measurement intrusion in parallel computations, but they are not sufficient. Depending on the application's parallel execution behavior, it is possible, even likely, that intrusion effects seen on different processes are interdependent. Consider the following scenario. A master process sends work to worker processes and then waits for their results. The worker processes do the work and send their results back to the master. A performance profile measurement is made with overhead compensation analysis. The workers see some percentage intrusion with the last worker to report seeing a 30% slowdown. The compensated profile analysis works well and accurately approximates the workers ``actual'' performance. The master measurement generates very little overhead because there are few events. However, because the master must wait for the worker results, it will be delayed until the last worker reports. Thus, its execution time will include the last worker's 30% intrusion! Our compensated estimate of the master's execution time will be unable to eliminate this error because it is unaware of the worker's overhead. We believe a very similar situation is occurring in some, if not all, of the parallel experiments reported here.
Figure 1 depicts the above scenario. Figure 1(a) shows the measured execution with time overhead indicated by rectangles and termination times by triangles. The large triangle marks where the program ends. The overhead for the master is assumed to be negligible. The arrows depict message communication. Figure 1(b) shows the execution with all the overhead bunched up at the end as a way to locate when the messages returning results from the workers (dashed arrows) would have been sent and the workers would have finished (small shaded triangles), if measurements had not been made. Profile analysis would correctly remove the overhead in worker performance profiles under these circumstances. However, the master knows nothing of the worker overheads and, thus, our current compensation algorithms cannot compensate for it. The master profile will still reflect the master finishing at the same time point, even though its ``actual'' termination point is much earlier.
Unfortunately, parallel overhead compensation is a more complex problem to solve. This is not entirely unexpected, given our past research on performance perturbation analysis [18,19,20]. However, in contrast with that work, we do not want to resort to a parallel trace analysis to solve it. The problem of overhead compensation in parallel profiling using only profile measurements (not tracing) has not been addressed before, save in a restricted form in Cray's MPP Apprentice system [29]. We are currently developing algorithms to do on-the-fly compensation analysis based on those used in trace-based perturbation analysis [25], but their utility will be constrained to deterministic parallel execution only, for the same reasons discussed in [17,25]. Implementation of these algorithms also will require techniques similar to those used in PHOTON [27] and CCIFT [2,3] to embed overhead information in MPI messages. While Photon extends the MPI header in the underlying MPICH implementation to transmit additional information, the MPI wrapper layer in the CCIFT application level checkpointing software allows this information to piggyback on each message.