Apart from a social reticence to accept solutions not developed within their own scientific communities, researchers are particularly concerned about the performance implications of a relatively new approach such as CBSE. Timescales for message-passing operations on modern supercomputers are measured in microseconds, and memory latencies in nanoseconds. The conventional rule of thumb is that environments that incur a performance cost in excess of 10 percent will be rejected outright by computational scientists. In addition, scientists are concerned about the impact of applying new techniques to extensive bases of existing code, often measured in hundreds of thousands of lines developed over a decade or more by small groups of researchers; extensive rewriting of code is expensive and rarely justifiable scientifically.
While there have been a number of experiments with commodity component models in a high-performance scientific context [1,2], so far they have not had noticeable acceptance in the scientific community. Unfortunately, various aspects of commercial component models tend to limit their direct applicability in high-performance scientific computing. Most have been designed primarily with distributed computing in mind, and many have higher overheads than desirable, even where multiple components within the same address space are supported. Support for parallel computing is also a crucial consideration. The effort required to adapt existing code to many commercial component models is often high, and some impose constraints with respect to languages and operating systems. For example, in high-end computational science, Java is still widely viewed as not providing sufficient performance, making an approach like Enterprise JavaBeans unattractive; and almost no supercomputers run Windows operating systems, limiting the applicability of COM.
The scientific high-performance computing (HPC) community has made some tentative steps toward componentlike models that are usually limited to a specific domain, for example Cactus [3], ESMF [4], and PALM/Prism [5]. While successful in their domains, these approaches do not support cross-disciplinary software reuse and interoperability.
In response, the Common Component Architecture Forum [6] was launched in 1998 as a grassroots initiative to bring the benefits of component-based software engineering to high-performance scientific computing. The CCA effort focuses first and foremost on developing a deeper understanding of the most effective use of CBSE in this area and is proceeding initially by developing an independent component model tailored to the needs of HPC.
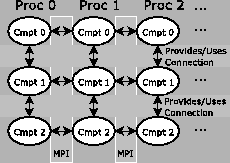
Space constraints require that we limit our presentation of the CCA here; however, further details are available at [6], and a comprehensive overview will be published soon [7]. The specification of the Common Component Architecture defines the rights, responsibilities, and relationships among the various elements of the model. Briefly, components are units of encapsulation that can be composed to form applications; ports are the entry points to a component and represent interfaces through which components interact--provides ports are interfaces that a component implements, and uses ports are interfaces that a component uses; and the framework provides some standard services, including instantiation of components, as well as uses and provides port connections.
The CCA employs a minimalist design philosophy to simplify the task of incorporating existing HPC software into the CCA environment. This approach is critical for acceptance in scientific computing. CCA-compliant components are required to implement just one method as part of the gov.cca.Component class: the component's setServices() method is called by the framework when the component is instantiated, and it is the primary means by which the component registers with the framework the ports it expects to provide and use. Uses ports and provides ports may be registered at any time, and with the BuilderService framework service it is possible programmatically to instantiate/destroy components and make/break port connections. This approach allows application assemblies to be dynamic, under program control, thereby permitting the computational quality-of-service work described in Section 3. Furthermore, this approach ensures a minimal overhead (approximately the cost of a virtual function call) for component interactions [8].
 |