In our earlier work (16), we developed techniques for quantifying the overhead of performance profile measurements and correcting the profiling results to compensate for the measurement error (i.e., overhead) introduced. This work was done for two types of profiles: flat profiles and profiles of routine calling paths. The techniques were implemented in the TAU profiling system and demonstrated on the NAS parallel benchmarks. However, the models we developed were based on a local perspective of how measurement overhead impacted the program's execution. Profiling measurements are, typically, performed for each program thread of execution. (Here we use the term ``thread'' in a general sense. Shared memory threads and distributed memory processes equally apply.) By a local perspective we mean one that only regards the overhead impact on the process (thread) where the profile measurement was made and overhead was incurred.
Consider a message passing parallel program composed of multiple processes. Most profiling tools would produce a separate profile for each process, showing how time was spent in its measured events. Because the profile measurements are made locally to a process (either through direct instrumentation or sampling), it is reasonable, as a first step, to compensate for measurement overhead in the process-local profiles only. Our original models did just that. They accounted for the measurement overhead generated during TAU profiling for each program process (thread) and all its measured events, and then removed the overhead from the inclusive and exclusive performance results calculated during online profiling analysis. The compensation algorithm ``corrected'' the measurement error in the process profiles in the sense that the local overhead was not included in the local profile results.
Indeed, the models we developed are necessary for compensating measurement intrusion in parallel computations, but they are not sufficient. Depending on the application's parallel execution behavior, it is possible, even likely, that intrusion effects due to measurement overhead seen on different processes will be interdependent. We use the term ``intrusion'' specifically here to point out that although measurement overhead occurs locally, its intrusion can have non-local effects.
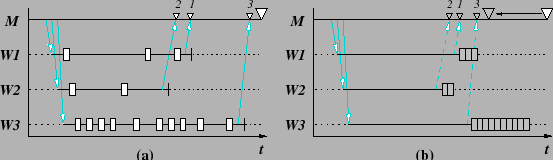
Suppose our message passing program implements a master-worker computation and consider the following execution scenario. The master process sends work to worker processes and then waits for their results. The worker processes do the work and send their results back to the master and terminate. The master finishes once all the worker results are received. Figure 1(a) depicts the above program execution with profiling enabled. The arrows show the master-to-worker and worker-to-master message communication and the local measurement overheads are shown by rectangles. The small triangles indicate when the worker messages are received by the master and the large triangle marks where the master terminates. Worker termination is depicted by the vertical line. Since no overhead compensation is performed in Figure 1(a), the total execution (worker and master) time is delayed. As shown, the overhead for the master process is assumed to be negligible, since for most of the time it is waiting for the workers to report their results.
Figure 1(b) portrays the effects of our original overhead compensation algorithms. Each worker is slowed down due to measurement overhead with the last worker to report seeing a 30% slowdown approximately. If we assume the local profile compensation works well and accurately approximates the workers ``actual'' performance, all the worker overhead will be removed. This is depicted by the overhead bunched up at the end of each worker's measured timeline. As a result, the messages returning results from the workers would have been sent earlier (dashed arrows) and the workers would have finished earlier, as if no measurements had been made. Because the master must wait for the worker results, it will be delayed until the last worker reports. Thus, its execution time will include the last worker's 30% intrusion. Unfortunately, the master knows nothing of the worker overheads and, thus, our ``local'' compensation algorithms cannot account for them. The master's profile will still reflect the master finishing at the same time point (white large triangle), even though its ``actual'' termination point is much earlier (grey large triangle).
Parallel overhead compensation is a more complex problem to solve. This is not entirely unexpected, given our past research on performance perturbation analysis (14,12,15). However, in contrast with that work, we do not want to resort to post-mortem parallel trace analysis to solve it. The problem of overhead compensation in parallel profiling using only profile measurements (not tracing) has not been addressed before, save in a very restricted form in Cray's MPP Apprentice system (25). Certainly, we can learn from techniques for trace-based perturbation analysis (22), but because we must perform overhead compensation on-the-fly, the utility of these trace-based algorithms will be constrained to deterministic parallel execution only, for the same reasons discussed in (13,22).
At a minimum, algorithms for on-the-fly overhead compensation in parallel profiling must utilize measurement infrastructure that conveys overhead information between processes at runtime. It is important to note this is not required for trace-based perturbation analysis and is what make compensation in profiling a unique problem. Techniques similar to those used in PHOTON (24) and CCIFT (2,3) to embed overhead information in MPI messages may aid in the development of such measurement infrastructure. Photon extends the MPI header in the underlying MPICH implementation to transmit additional information. In contrast, the MPI wrapper layer in the CCIFT application level checkpointing software allows this information to piggyback on each message.
However, we first need the understand how local measurement overhead affects global performance intrusion so that we can construct compensation models and use those models to develop online algorithms.