To address the dual goals of performance technology for complex systems -- robust performance capabilities and widely available performance problem solving methodologies -- we need to contend with problems of system diversity while providing flexibility in tool composition, configuration, and integration. One approach to address these issues is to focus attention on a sub-class of computation models and performance problems as a way to restrict the performance technology requirements. The obvious consequence of this approach is limited tool coverage. Instead, our idea is to define an abstract computation model that captures general architecture and software execution features and can be mapped straightforwardly to existing complex system types. For this model, we can target performance capabilities and create a tool framework that can adapt and be optimized for particular complex system cases.
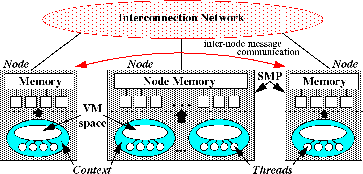
Figure: Execution model supported by the TAU Performance System
Our choice of general computation model must reflect real computing environments. The computational model we target was initially proposed by the HPC++ consortium [4] and is illustrated in Figure 2.1. Two combined views of the model are shown: a physical (hardware) view and an abstract software view. In the model, a node is defined as a physically distinct machine with one or more processors sharing a physical memory system (i.e., a shared memory multiprocessor (SMP)). A node may link to other nodes via a protocol-based interconnect, ranging from proprietary networks, as found in traditional MPPs, to local- or global-area networks. Nodes and their interconnection infrastructure provide a hardware execution environment for parallel software computation. A context is a distinct virtual address space within a node providing shared memory support for parallel software execution. Multiple contexts may exist on a single node. Multiple threads of execution, both user and system level, may exist within a context; threads within a context share the same virtual address space. Threads in different contexts on the same node can interact via inter-process communication (IPC) facilities, while threads in contexts on different nodes communicate using message passing libraries (e.g., MPI) or network IPC. Shared-memory implementations of message passing can also be used for fast intra-node context communication. The bold arrows in the figure reflect scheduling of contexts and threads on the physical node resources.