Because TAU supports a general parallel computation model, it can configure the measurement system to capture both thread and communication performance information. We have demonstrated the ability to form an integrated performance measurement for applications that use OpenMP for shared memory parallel programming and MPI for cross-node message-based parallelism. Figure 4.4 shows a performance trace of a ocean circulation application based on a 2D Stommel model using Jacobi iteration on a 5-point stencil. Notice the integrated identification of OpenMP and MPI events. Also, we can see parallel thread execution (``Process i'' in the figure) interposed between regions of message communication conducted by the main threads (``Process 0'' in the figure). The Vampir timeline display at the bottom shows that the main thread on Node 0 spends the majority of its time in communication.
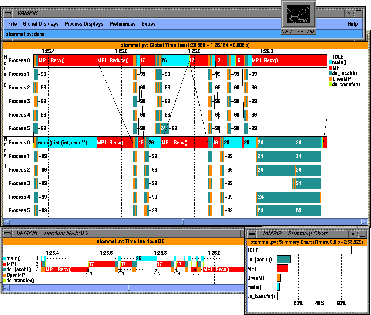
Figure: Mixed-mode OpenMP / MPI execution trace of ocean circulation
application
To observe hardware performance for the parallel OpenMP sections of the computation, we can switch the TAU measurement system without change to the instrumentation. Figure 4.5 shows the performance profile of floating-point instructions. In comparing the main thread (labeled n,c,t 0,0,0) with thread 1 (labeled n,c,t 0,0,1), we can see that the floating-point operations are the same for the OpenMP Parallel for region and the do_jacobi routines, but the main thread calculates do_force alone as well as performs all communication.
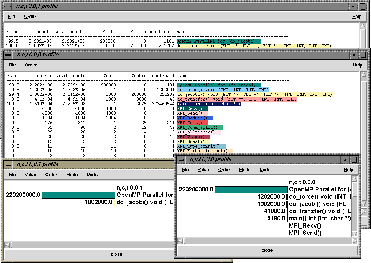
Figure: Mixed-mode OpenMP / MPI execution profile of ocean circulation
application with floating-point counts