At the heart of the abstract model is the claim that if performance visualization is to play a key role in the evaluation of parallel computers and programs, then it must be established on a formal foundation that relates abstract performance behavior to visual representations (i.e., a "visual performance abstraction"). The binding of a performance abstraction to a view abstraction, mapping performance object outputs to view object inputs, represents a performance visualization [28].
The notion of viewing a performance visualization as a mapping from performance data to a graphical representation was introduced in Chapter I. The absence of concrete, physical models to contextualize performance visualizations implies that such displays may take on a more abstract, impressionistic nature, potentially complicating interpretation and usability. By imposing an abstract model (i.e., structure) onto the development of performance visualizations, some of these inherent difficulties may be overcome. By providing a set of graphical techniques and a robust environment for mapping performance data onto them, visualization flexibility is maintained, but structure is preserved. In other words, the user is provided with a fixed set of visual techniques rather than a fixed set of visualizations. Some preliminary research suggests, for example, that a vast array of visualizations can be modelled as hierarchical graphs of nodes and links.
A performance abstraction is the representation of how performance complexity is managed (i.e., desired performance data analysis) and the performance characteristics to be observed. A view abstraction is a representation of the desired visual form of the abstracted performance data, unconstrained by the limitations of the graphics environment. Together, these two descriptions can be used to produce performance visualization software by generating interfaces to available graphical programming libraries or existing data visualization systems. Using this methodology, new parallel performance visualization environments can be developed and studied.
As seen in Figure 1, through a process of abstraction, performance data generates specifications for the performance analysis and the visual representation of the data. In practice, these abstractions would best be facilitated through a specification language (which is currently under development at the University of Oregon); the particular implementation environment, Data Explorer, does not currently offer support for this aspect of the methodology. Specifications are subsequently instantiated to implementable objects. (The term objects is intentionally general to accommodate the many realizations possible in different implementation environments.) Figure 1 indicates an overlap between performance and view objects, suggesting an interdependence between their implementations. In the ideal implementation environment, performance and view objects would be totally independent, but this research has found that the degree to which these entities can be implemented independent of one another is determined by the environment in which the implementation is taking place. In Data Explorer, this overlap is present in varying degrees. Next, the instantiated objects are combined to create the visual representation of the performance data. Finally, the actual rendering of the visualization takes place through a toolkit which interfaces with the various graphics resources being utilized. The explicit existence of the toolkit is also dependent on the implementation environment (e.g., in Data Explorer, the "toolkit" interface is imbedded within the visualization system itself). For more information about this methodology, see [28].
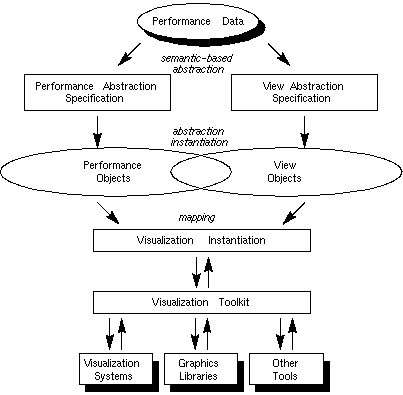
Figure 1. A high-level, abstract view of performance visualization treats a visualization as a mapping from performance data objects to graphical view objects and promotes the development of interfaces to existing graphical resources.The research documented in this thesis is concerned with the application of this methodology in a specific implementation environment - a scientific visualization software system; in this case, that system is Data Explorer. As mentioned earlier, realizing this methodology in a specific environment is not always straightforward, and the correlation between abstraction and implementation is not always cleanly defined. It was mentioned above that Data Explorer does not offer support for the specification of abstractions, and consequently, this was not the focus of this research effort. On the other hand, it was possible to implement the concepts of performance and view objects in the context of an existing data visualization system. The process that has evolved implements performance objects by structuring raw trace data so that the visualization system can process it. View objects manifest themselves in the way a developer creates a visualization within Data Explorer. These correlations will be explained further in the next chapter.