
pC++ is an object-parallel programming language intended for both shared and distributed memory machines. It extends the notion of data-parallel execution to aggregates; that is, structured sets of objects distributed over the processors of a parallel system. Application-specific aggregates are described in pC++ as collection class types. Parallelism is implicit and results from the concurrent application of a function to the elements of a collection. pC++ provides a shared name space; references to shared data compile to GET_ELEMENT routines that generate (at runtime) explicit sends and receives for nonlocal data.
Event traces from a pC++ program include these generated events, each tagged
with the type of operation it implements (for example, W_ASKFORDATA, R_STOREBLOCKMSG, and W_ACKREPLYMSG ). Thus the trace exposes the
workings of the runtime system to the programmer, which is sometimes useful
in debugging. For the most part, however, it is not. The majority of pC++
programmers understand their code only at the higher level of data-parallel
operations and those operations must be accessible during debugging.
). Thus the trace exposes the
workings of the runtime system to the programmer, which is sometimes useful
in debugging. For the most part, however, it is not. The majority of pC++
programmers understand their code only at the higher level of data-parallel
operations and those operations must be accessible during debugging.
Ariadne's predefined event set can be extended dynamically, without requiring a recompilation of the debugger. This enables us to add higher-level pC++ events as predefined user events, leaving the debugger itself independent of the source language. For pC++, the predefined events include
We also allow ordinary user events which can be inserted into
pC++ source code in standard functions, in methods of elements (invoked by each element of a
collection), or in member functions (invoked on a per process basis). This
gives us three levels of abstraction in traced events:
runtime communication events, pC++ predefined events, and user events.
Ariadne filters unwanted events from a match, making it possible to use
events from different levels separately or in combination.
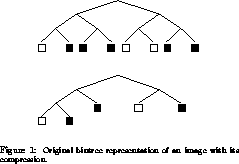
Example: Binary Image Compression. To illustrate the use of
Ariadne and the extended modeling language, we debug a parallel version of
an algorithm to compress black and white images stored as bintrees
[22]. Working up from the leaves, the algorithm compresses
homogeneously colored siblings into single nodes represented at their
parent as shown in Figure 1. The parallel version of the algorithm distributes entire subtrees
of the initial bintree to processes. We ran our code on images with 256 nodes.
It ran to completion but frequently produced compressions that were too
small.
To begin debugging this program with Ariadne, we added user-defined events
USERMERGE and USERNOMERGE to trace the decisions made about
each pair of siblings. The behavior of a single node during a step in which
it is active was then described by one of the two chains
CH MERGE =
USERMERGE WRT [ ];
mentioned in the pattern are to be ignored.
pC++ distributes the elements of a collection across the processors and uses
an ``owner computes'' rule. In this case, elements of the collection
correspond to the active nodes of the bintree; initially the leaves are
active. Processors iterate through the elements assigned to them. To model
the combined behavior of the nodes across a level of the tree, we first
define the successful completion of a barrier synchronization as
CH BARRIER = BEGINBARRIER ENDBARRIER WRT [ ];
PCH COMPRESSLEVEL =
The behavior of the algorithm as a whole is modeled as
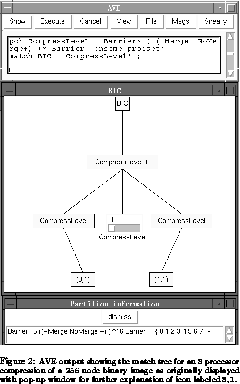
As mentioned above, matching imposes a tree structure on the matched subgraph that corresponds
to the model's structure. It is this match
tree that is displayed by AVE in the figure. For scalability, it is automatically
compressed both horizontally and vertically: horizontally by eliding sibling
nodes and vertically by pruning levels. The horizontal compression is
straightforward: omitted siblings are represented by a single slider. In our example, the
match tree included 8 instances of the COMPRESSLEVEL p-chain but
only the first and last are explicitly shown in the initial picture.
Vertical compression is achieved by pruning subtrees below each p-chain.
The pruned subtrees are partitioned into equivalence classes and represented
by an icon labeled with a pair of integers that summarizes the partitioning:
the first element is the total number of chain subtrees represented and the
second is the number of equivalence classes of those trees. In the example,
the leftmost box is labeled with 8,1 which indicates that 8 processes
initiated a COMPRESSLEVEL event and all of them matched the same
p-chain pattern. The pop-up window below (obtained by clicking on the icon)
gives a further description of this subtree: a pattern matching 5 barrier
events, followed by 16 compression events (either MERGE or
NOMERGE), followed by another barrier was matched on processes 0
through 7. This is as expected. In the first step of the compression, each
process handles 32 leaf nodes of the image, performing 16 compression
operations. In the last step, only one process is active as evidenced by
the 1,1 label on its node.
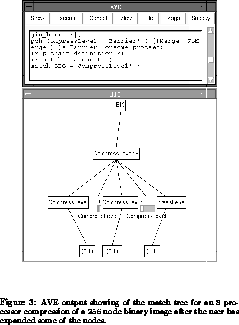
Intermediate nodes of the tree can be viewed as in Figure 3.
It shows the third node also expanded. The third node again has all eight
processes active because they are still handling local subtrees. Eventually,
the local subtrees are compressed and at the later stages of the program,
processes become inactive; if we looked at the events of the seventh and
eighth stages, for example, we would have seen that only two processes were
active in the seventh and only one in the eighth.
So far, our debugging output is as expected, the model matched the traced
behavior. Ariadne's models, however, are quite coarse and it is often useful
to investigate a match further using its query facilities. In this case,
because we knew that the resulting compressed image was too small, we were
suspicious that erroneous, extra MERGE events were occurring.
To check this, we wanted to determine the number of elements executing MERGE events in each
COMPRESSLEVEL. First, we defined an additional attribute,
MERGELTS, for
MERGE nodes using
which first counts the number of elements performing MERGE events in
each COMPRESSLEVEL (that is, computes the size of the set of all
elements IDs) and then displays the output as in
Figures 4(a) and 4(b). These
plots were not as expected. At each level in the bintree, only those
nodes that were successfully merged at the previous level are available for
merger;
thus, the number of
successful merges at any level should be no more than half the number from the previous
step. Figure 4(a) shows roughly the decreasing values that we
would expect but looking at the actual values in Figure 4(b),
we see a problem. 32
events were compressed at the third level but this is more than half of the
63 that had been compressed at the second level. There were too
many MERGEs on the third level.
Perhaps the program was incorrectly merging siblings with different color
values. To check out this possibility, we replayed the execution (as
discussed in the next section) annotating the traced MERGE
events with the color values of the subtrees being merged. We then
rematched the model against the trace and asked if MERGE events
only occurred at like-colored siblings. The answer was ``yes.'' We next
investigated the possibility that some of the mergers were invalid because
one of the siblings represented a subtree where compression had already
failed at a lower level. This would result in a NOMERGE event
being followed by a subsequent MERGE event on the same
element. To check this, we first computed
Further investigations with Ariadne were not productive. This, however, is
typical: event-based debugging is useful in narrowing the focus of attention
during the early stages of debugging but it is not as useful in relating the
detected anomalies back to source code errors in the later stages of
debugging. As the result of our event-based analysis, we know that the code merged nodes representing trees when it should have only merged nodes representing single, fully compressed leaves. We also know that this was first
detectable on level three. We don't, however, know why it occurred. For this, we
switched to a state-based debugger.
CH NOMERGE =
USERNOMERGE WRT [ ];
where CH is a keyword that begins the definition of a
chain and the WRT clause indicates that event types not
explicitly
and then model the complete behavior at a single level as
BARRIER* ( (+ MERGE NOMERGE +) ) * BARRIER
ONSOME PROCSET;
where PCH is a keyword that begins the definition of a p-chain,
(+ A B +) denotes the regular expression A + B , * denotes the Kleene star, and ONSOME indicates that the
pattern occurs on some, but not necessarily all, of the specified
processes. Since
we ran our code on an SGI PowerChallenge with 8 processors, we used the set
of process ids PROCSET = {0..7} for this example. It should
be noted that
ONSOME was quite useful here because at the later stages of
the algorithm, subsequent steps involve fewer processes and thus it
allows us to specify a single model for all steps.
MATCH BIC =
COMPRESSLEVEL* ;
where MATCH is a keyword indicating that the specified
pattern (0 or more instances of COMPRESSLEVEL) is to be matched
in the execution history graph and the resulting subgraph is to be assigned
to the specified variable, BIC. Note that the model is
scalable: it is completely insensitive to the input size and
only the definition of PROCSET depends on the machine size.
Figure 2
shows a match of this model to an execution.
WITH BIC FOREACH MERGE
COMPUTE MERGELTS = ELEMID(USERMERGE);
which computes the element ID attribute (ELEMID) from
the
corresponding matched trace
events. Our query was then
WITH BIC FOREACH COMPRESSLEVEL
COMPUTE
.5IN NUMMERGES = SIZEOF(MERGELTS(MERGE));
WITH BIC SHOW NUMMERGES (COMPRESSLEVEL)
.5IN WRT COMPRESSLEVEL;
WITH BIC FOREACH NOMERGE COMPUTE
NOMERGELTS = ELEMID(USERNOMERGE);
as above and then computed the set of elements having each outcome as
WITH BIC FOREACH COMPRESSLEVEL
COMPUTE
MERGESET = MERGELTS(MERGE);
WITH BIC FOREACH COMPRESSLEVEL
COMPUTE
NOMERGESET = NOMERGELTS(NOMERGE);
None of the elements with MERGE events on a level
should
have participated in the
NOMERGE events on the previous level. In terms of our sets,
this means that MERGESETs
should be disjoint from the NOMERGESETs on the previous level. We checked this with the query
WITH BIC FOREACH COMPRESSLEVEL COMPUTE
.4IN MERGEFLAG =
DISJOINT(MERGESET(COMPRESSLEVEL),
NOMERGESET(LEFT(COMPRESSLEVEL)));
WITH BIC SHOW MERGEFLAG(COMPRESSLEVEL)
WRT BIC;
where LEFT here refers to the immediately preceding COMPRESSLEVEL event (that is, its left sibling in the match tree). This query produced the output in
Figure 5 showing that the sets on the third level were
not disjoint as they should have been. (We knew this because the output
value for the third level was ``0'' indicating that the DISJOINT predicate was false.) Thus some element on level three did a
compression on a subtree that had not been compressed at level two.
Next: Setting Consistent Breakpoints
Up: Event and State-Based Debugging
Previous: The Ariadne Debugger:
Sameer Suresh Shende
Fri Apr 5 10:36:18 PST 1996