 [bigger image]
[bigger image]
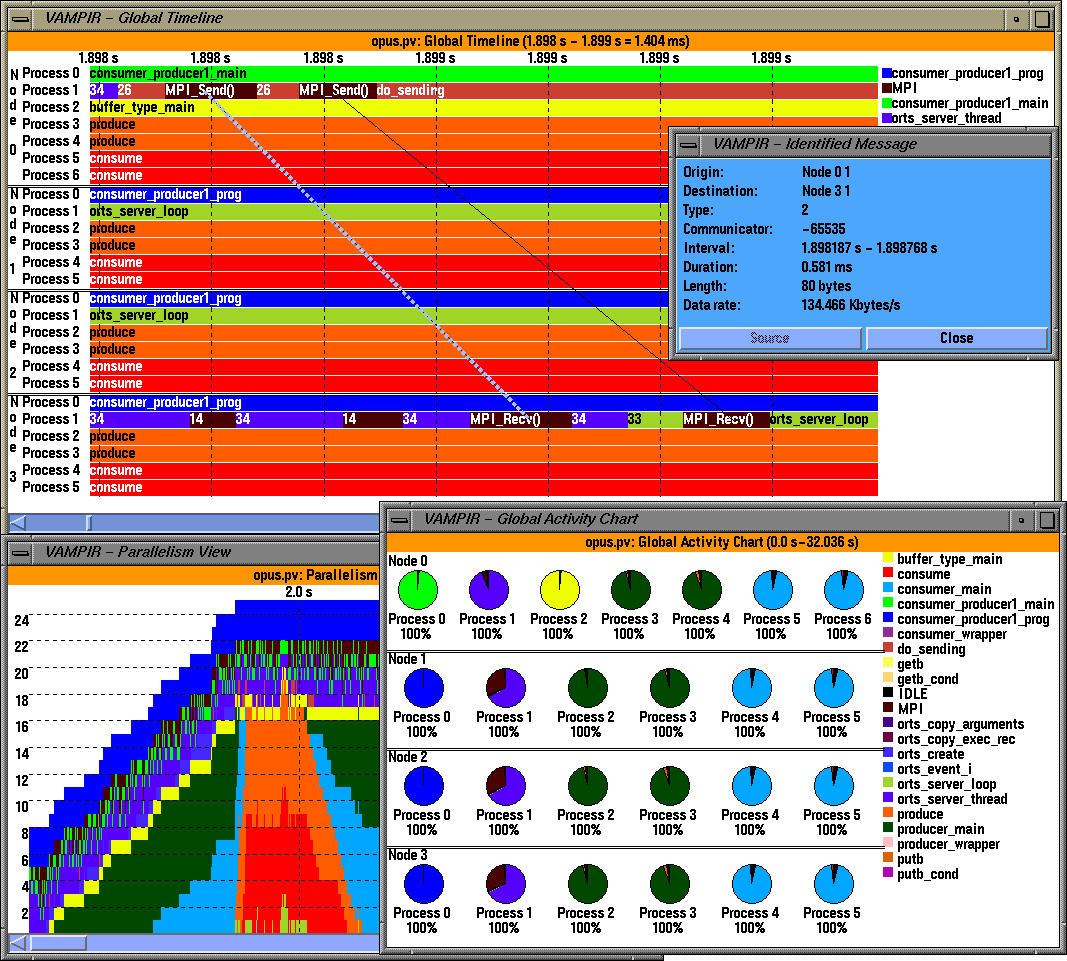
Figure: Vampir displays for TAU traces of an Opus/HPF application using MPI and pthread
Increasingly, scalable parallel systems are being designed as clusters of shared memory multi-processors (SMPs), with MPI or some other inter-process communication paradigm used for message passing between SMP nodes, and thread-based shared memory programming used within the SMP. Runtime systems are built to hide the intricacies of efficient communication, presenting a compiler backend or an application programmer with a set of well-defined, portable interfaces. Performance measurement and analysis tools must embed the hierarchical, hybrid execution model of the application within their performance model. Because TAU supports a general parallel computation model, it can configure the measurement system to capture both thread and communication performance information. However, this information must be mapped to the programming model. We have used TAU to investigate task and data parallel execution in the Opus/HPF programming system [4]. Figure 1.3 shows a Vampir display of TAU traces generated from an application written using HPF for data parallelism and Opus for task parallelism. The HPF compiler produces Fortran 90 data parallel modules which execute on multiple processes. The processes interoperate using the Opus runtime system built on MPI and pthreads. In systems of this type, it is important to be able to see the influence of different software levels. TAU is able to capture performance data at different parts of the Opus/HPF system exposing the bottlenecks within and between levels.