


Next: Large-Scale Performance Monitoring and
Up: paper-final
Previous: Measurement Overhead and Instrumentation
To observe meaningful performance events requires placement of
instrumentation in the program code. However, not all information
needed to interpret an event of interest is available prior to
execution. A good example of this occurs in callgraph profiling.
Here the objective is to determine the distribution of execution time
along the dynamic routine calling paths of an application. A callpath
of length 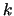 is a sequence of the last
is a sequence of the last 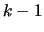 routines called. To
measure execution time spent on a callpath requires identifying the
begin and end points during which a callpath is ``active.'' These
points are just the entry and exit of a called routine. If
routines called. To
measure execution time spent on a callpath requires identifying the
begin and end points during which a callpath is ``active.'' These
points are just the entry and exit of a called routine. If 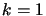 ,
callpath profiling is the measurement of amount of time spent in a
routine for each of its calling parents. The basic problem with
callpath profiling is that the identities of all -length calling
paths ending at a routine may not, and generally are not, known until
the application finishes its execution. How, then, do we identify the
dynamic callpath events in order to make profile measurements?
One approach is not to try to not identify the callpaths at runtime,
and instead instrument just basic routine entry and exit events and
record the events in a trace. Trace analysis can then easily
calculate callpath profiles. The problem, of course, with this
approach is that the trace generated may be excessively large,
particularly for large numbers of processors. Unfortunately, the
instrumentation and measurement problem is significantly harder if
callpath profiles are calculated online.
If the whole source is available, it is possible to determine the
entire static callgraph and enumerate all possible callpaths, encoding
this information in the program instrumentation. These callpaths are
static, in the sense that they could occur; dynamic callpaths are the
subset of static callpaths that actually do occur during execution.
Once a callpath is encoded and stored in the program, the dynamic
callpath can then be determined directly by indexing a table of
possible next paths using the current routine id. Once the callpath
is known, the performance information can be easily recorded in
pre-reserved static memory. This technique was used in the CATCH tool
[5].
Unfortunately, this is not a robust solution for several
reasons. First, source-based callpath analysis is non-trivial and may
be only available for particular source languages, if at all. Second,
the application source code must be available if a source-based
technique is used. Third, static callpath analysis is possible at the
binary code level, but the routine calls must be explicit and not
indirect. This complicates C++ callpath profiling, for instance.
To deliver a robust, general solution, we decided to pursue an
approach where the callpath is calculated and queried at runtime. The
TAU measurement system already maintains a callstack that is updated
with each entry/exit performance event (e.g., routine entry and exit).
Thus, to determine the -length callpath when a routine is entered,
all that is necessary is to traverse up the callstack to determine the
last events that define the callpath. If this is a newly
encountered callpath, a new measurement profile must be created at
that time because it was not pre-allocated. The main problem is how
to do all of this efficiently.
Mapping callpath identity to its profile measurement is an example of
what we call performance mapping. TAU implements a performance
mapping API based on the Semantic Event Association and
Attribute (SEAA) model [14]. Here an association is built between
the identity of a performance event (e.g., a callpath) and a
performance measurement object (e.g., a profile) for that event.
Thus, when the event is encountered, the measurement object linked to
that event can be found, via a lookup in a mapping table, and the
measurement made.
In the case of callpath performance mapping, new callpaths occur
dynamically, requiring new profile objects to be created at runtime.
This can be done efficiently using the TAU mapping API. The callpath
name is then hashed to serve as the index for future reference.
Because routine identifiers can be long strings, TAU optimizes this
process by computing the hash based on addresses of the profile
objects of its parents. While the extra overhead to perform this
operation is fixed, the accumulated overhead will depend on the number
of unique -length callpaths encountered in the computation, as each
of these will need a separate profile object created.
We have implemented 2-level callpath profiling in TAU as part of the
current TAU performance system distribution. The important result is that
this capability is available in all cases where TAU profiling is available.
It is not restricted by programming language, nor source code access
required, as dynamic instrumentation (via DyninstAPI [4]) can be
used when source is not available. Also, all types of performance
measurements are allowed, including measuring hardware counts for each
callpath. Finally, in the future, we can benefit from the overhead
reduction mechanisms to eliminate particular callpaths from measurement
consideration.
Unfortunately, unlike a static approach, the measurement overhead of
this dynamic approach increases as increases because we must walk
the callstack to determine the callpath. We have discussed several
methods to do this more efficiently, but none lead to a fixed overhead
for any , and adopting a general solution for the 2-level case
would result in greater cost. Most user requests were for 2-level
callpaths to determine routine performance distribution across calling
parents, and this is what has been implemented in TAU. It should be
noted that there are no inherent limitations to implementing solutions
with
,
callpath profiling is the measurement of amount of time spent in a
routine for each of its calling parents. The basic problem with
callpath profiling is that the identities of all -length calling
paths ending at a routine may not, and generally are not, known until
the application finishes its execution. How, then, do we identify the
dynamic callpath events in order to make profile measurements?
One approach is not to try to not identify the callpaths at runtime,
and instead instrument just basic routine entry and exit events and
record the events in a trace. Trace analysis can then easily
calculate callpath profiles. The problem, of course, with this
approach is that the trace generated may be excessively large,
particularly for large numbers of processors. Unfortunately, the
instrumentation and measurement problem is significantly harder if
callpath profiles are calculated online.
If the whole source is available, it is possible to determine the
entire static callgraph and enumerate all possible callpaths, encoding
this information in the program instrumentation. These callpaths are
static, in the sense that they could occur; dynamic callpaths are the
subset of static callpaths that actually do occur during execution.
Once a callpath is encoded and stored in the program, the dynamic
callpath can then be determined directly by indexing a table of
possible next paths using the current routine id. Once the callpath
is known, the performance information can be easily recorded in
pre-reserved static memory. This technique was used in the CATCH tool
[5].
Unfortunately, this is not a robust solution for several
reasons. First, source-based callpath analysis is non-trivial and may
be only available for particular source languages, if at all. Second,
the application source code must be available if a source-based
technique is used. Third, static callpath analysis is possible at the
binary code level, but the routine calls must be explicit and not
indirect. This complicates C++ callpath profiling, for instance.
To deliver a robust, general solution, we decided to pursue an
approach where the callpath is calculated and queried at runtime. The
TAU measurement system already maintains a callstack that is updated
with each entry/exit performance event (e.g., routine entry and exit).
Thus, to determine the -length callpath when a routine is entered,
all that is necessary is to traverse up the callstack to determine the
last events that define the callpath. If this is a newly
encountered callpath, a new measurement profile must be created at
that time because it was not pre-allocated. The main problem is how
to do all of this efficiently.
Mapping callpath identity to its profile measurement is an example of
what we call performance mapping. TAU implements a performance
mapping API based on the Semantic Event Association and
Attribute (SEAA) model [14]. Here an association is built between
the identity of a performance event (e.g., a callpath) and a
performance measurement object (e.g., a profile) for that event.
Thus, when the event is encountered, the measurement object linked to
that event can be found, via a lookup in a mapping table, and the
measurement made.
In the case of callpath performance mapping, new callpaths occur
dynamically, requiring new profile objects to be created at runtime.
This can be done efficiently using the TAU mapping API. The callpath
name is then hashed to serve as the index for future reference.
Because routine identifiers can be long strings, TAU optimizes this
process by computing the hash based on addresses of the profile
objects of its parents. While the extra overhead to perform this
operation is fixed, the accumulated overhead will depend on the number
of unique -length callpaths encountered in the computation, as each
of these will need a separate profile object created.
We have implemented 2-level callpath profiling in TAU as part of the
current TAU performance system distribution. The important result is that
this capability is available in all cases where TAU profiling is available.
It is not restricted by programming language, nor source code access
required, as dynamic instrumentation (via DyninstAPI [4]) can be
used when source is not available. Also, all types of performance
measurements are allowed, including measuring hardware counts for each
callpath. Finally, in the future, we can benefit from the overhead
reduction mechanisms to eliminate particular callpaths from measurement
consideration.
Unfortunately, unlike a static approach, the measurement overhead of
this dynamic approach increases as increases because we must walk
the callstack to determine the callpath. We have discussed several
methods to do this more efficiently, but none lead to a fixed overhead
for any , and adopting a general solution for the 2-level case
would result in greater cost. Most user requests were for 2-level
callpaths to determine routine performance distribution across calling
parents, and this is what has been implemented in TAU. It should be
noted that there are no inherent limitations to implementing solutions
with 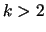 . Also, if it is possible to determine callpaths
statically, TAU could certainly use that information to implement a
fixed-cost solution.
. Also, if it is possible to determine callpaths
statically, TAU could certainly use that information to implement a
fixed-cost solution.
Next: Large-Scale Performance Monitoring and
Up: paper-final
Previous: Measurement Overhead and Instrumentation
Sameer Suresh Shende
2003-02-21