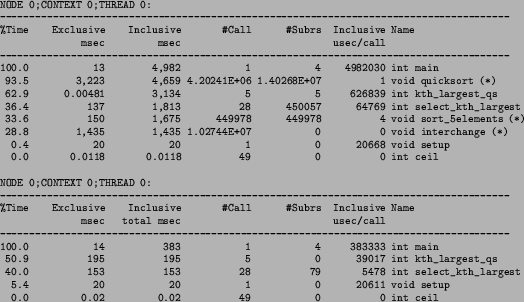
| Description |
Rule |
| Exclude all events that are members of the TAU_USER group
and use less than 100 microseconds |
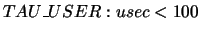 |
| Exclude all events that have less than 100 microseconds and are
called only once |
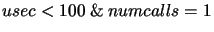 |
| Exclude all events that have less than 100 microseconds |
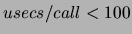 |
| per call or have a total inclusive percentage less than 5 |
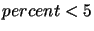 |